 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausaLab: A Scalable Environment for Interactive Causal Discovery Toward AI Scientists
May 28, 2026We introduce CausaLab, a scalable environment for evaluating interactive causal discovery by LLM agents. Unlike prior evaluations, CausaLab evaluates both whether an agent can solve a problem using causal evidence and whether its answer is grounded in a faithful recovered causal mechanism. Each episode places an agent in a synthetic laboratory: it receives prior measurement records, intervenes on a manipulator crystal, and predicts the resonance frequency of a held-out reactor crystal governed by the same mechanism. The hidden data-generating process is a randomly sampled structural causal model (SCM), so success requires recovering both a causal graph and structural equations rather than recalling prior knowledge. Experiments show a persistent gap between prediction and mechanism recovery: in the purely observational 6-node setting, GPT-5.2-high reaches 92% task accuracy but only 0.471 all-edge $F_1$. Mixed observation-intervention strategies improve structural fidelity, while pure intervention remains difficult even for strong agents. We identify premature stopping as a major weakness and show that consistency verification mitigates it. CausaLab therefore separates predictive success from causal understanding and exposes current LLM agents' limits as experimental causal reasoners.
FM-fMRI: Event Conditioned Flow Matching for Rest-to-Task fMRI Time-Series Synthesis
May 26, 2026Task-based fMRI provides a direct readout of task-evoked neural dynamics, but it is expensive and difficult to acquire at scale, motivating rest-to-task synthesis from widely available resting-state fMRI (rsfMRI). We propose FM-fMRI, an event-conditioned flow-matching model that learns a continuous-time conditional vector field to generate task ROI time series from a subject's rsfMRI and the task event information. The formulation enables fast ODE-based sampling and flexible conditioning over heterogeneous event schedules. Rather than optimizing for pointwise reconstruction, we evaluated generated signals using complementary criteria that probe temporal and spectral structure, subject and group-level connectome consistency, and distributional alignment. On the public Human Connectome Project and internal BioPoint autism cohort, FM-fMRI achieves the strongest spectral and connectivity agreement and improved distribution-level matching over conditional diffusion, generative adversarial networks (GANs), and variational autoencoders (VAEs) baselines. Furthermore, we augment the BioPoint cohort by synthesizing task-fMRI ROI time series with our method, improving downstream autism classification and demonstrating practical utility in data-limited clinical settings. The code will be available on GitHub.
BioFact-MoE: Biologically Factorized Mixture of Experts for Vision-Language Prognostic Modeling in Hepatocellular Carcinoma
May 25, 2026Hepatocellular carcinoma (HCC) is biologically heterogeneous, shaped by the interplay between hepatic functional reserve and tumor-related oncologic factors; thus, similar survival outcomes may reflect fundamentally different underlying biological processes. Prognostic modeling in HCC is informed by rich multimodal information from multiparametric MRI and radiology reports from routine clinical practice. Existing prognostic vision-language models (VLMs) learn a single entangled latent representation that blends hepatic and tumor-related factors, limiting both accuracy and biological interpretability. We present BioFact-MoE, a biologically factorized Mixture of Experts (MoE) framework that explicitly decomposes liver and tumor factors via biologically supervised experts within a residual MoE survival architecture. On a HCC cohort of N=588 patients (pretrained on 4,582 3D MRI image-report pairs), BioFact-MoE consistently improves survival prediction over all baselines across time horizons, achieving 12-, 18-, and 24-month AUCs of 75.33%, 75.85%, and 73.96%. Beyond scalar risk prediction, gated expert weights enable phenotype-aware risk stratification. Pathway-informed gating uncovers clinically meaningful treatment-associated survival heterogeneity. In held-out validation, hepatic and tumor embeddings show selective associations with liver function and tumor burden markers, respectively (p<0.05), without supervision. The code is available at https://github.com/jy-639/BioFact-MoE.
Post-Trained MoE Can Skip Half Experts via Self-Distillation
May 18, 2026Mixture-of-Experts (MoE) scales language models efficiently through sparse expert activation, and its dynamic variant further reduces computation by adjusting the activated experts in an input-dependent manner. Existing dynamic MoE methods usually rely on pre-training from scratch or task-specific adaptation, leaving the practical conversion of fully trained MoE underexplored. Enabling such adaptation would directly alleviate the inference costs by allowing easy tokens to bypass unnecessary expert during serving. This paper introduces Zero-Expert Self-Distillation Adaptation (ZEDA), a low-cost framework that transforms post-trained static MoE models into efficient dynamic ones. To stabilize this architectural conversion, ZEDA injects parameter-free zero-output experts into each MoE layer and adapts the augmented model through two-stage self-distillation, utilizing the original MoE as a frozen teacher and applying a group-level balancing loss. On Qwen3-30B-A3B and GLM-4.7-Flash across 11 benchmarks spanning math, code, and instruction following, ZEDA eliminates over 50% of expert FLOPs at marginal accuracy loss. It outperforms the strongest dynamic MoE baseline by 6.1 and 4.0 points on the two models, and delivers ~1.20$\times$ end-to-end inference speedup.
How Far Can Unsupervised RLVR Scale LLM Training?
Mar 09, 2026Unsupervised reinforcement learning with verifiable rewards (URLVR) offers a pathway to scale LLM training beyond the supervision bottleneck by deriving rewards without ground truth labels. Recent works leverage model intrinsic signals, showing promising early gains, yet their potential and limitations remain unclear. In this work, we revisit URLVR and provide a comprehensive analysis spanning taxonomy, theory and extensive experiments. We first classify URLVR methods into intrinsic versus external based on reward sources, then establish a unified theoretical framework revealing that all intrinsic methods converge toward sharpening the model's initial distribution This sharpening mechanism succeeds when initial confidence aligns with correctness but fails catastrophically when misaligned. Through systematic experiments, we show intrinsic rewards consistently follow a rise-then-fall pattern across methods, with collapse timing determined by model prior rather than engineering choices. Despite these scaling limits, we find intrinsic rewards remain valuable in test-time training on small datasets, and propose Model Collapse Step to measure model prior, serving as a practical indicator for RL trainability. Finally, we explore external reward methods that ground verification in computational asymmetries, showing preliminary evidence they may escape the confidence-correctness ceiling. Our findings chart boundaries for intrinsic URLVR while motivating paths toward scalable alternatives.
OpenCUA: Open Foundations for Computer-Use Agents
Aug 12, 2025Vision-language models have demonstrated impressive capabilities as computer-use agents (CUAs) capable of automating diverse computer tasks. As their commercial potential grows, critical details of the most capable CUA systems remain closed. As these agents will increasingly mediate digital interactions and execute consequential decisions on our behalf, the research community needs access to open CUA frameworks to study their capabilities, limitations, and risks. To bridge this gap, we propose OpenCUA, a comprehensive open-source framework for scaling CUA data and foundation models. Our framework consists of: (1) an annotation infrastructure that seamlessly captures human computer-use demonstrations; (2) AgentNet, the first large-scale computer-use task dataset spanning 3 operating systems and 200+ applications and websites; (3) a scalable pipeline that transforms demonstrations into state-action pairs with reflective long Chain-of-Thought reasoning that sustain robust performance gains as data scales. Our end-to-end agent models demonstrate strong performance across CUA benchmarks. In particular, OpenCUA-32B achieves an average success rate of 34.8% on OSWorld-Verified, establishing a new state-of-the-art (SOTA) among open-source models and surpassing OpenAI CUA (GPT-4o). Further analysis confirms that our approach generalizes well across domains and benefits significantly from increased test-time computation. We release our annotation tool, datasets, code, and models to build open foundations for further CUA research.
Scaling Computer-Use Grounding via User Interface Decomposition and Synthesis
May 19, 2025Graphical user interface (GUI) grounding, the ability to map natural language instructions to specific actions on graphical user interfaces, remains a critical bottleneck in computer use agent development. Current benchmarks oversimplify grounding tasks as short referring expressions, failing to capture the complexity of real-world interactions that require software commonsense, layout understanding, and fine-grained manipulation capabilities. To address these limitations, we introduce OSWorld-G, a comprehensive benchmark comprising 564 finely annotated samples across diverse task types including text matching, element recognition, layout understanding, and precise manipulation. Additionally, we synthesize and release the largest computer use grounding dataset Jedi, which contains 4 million examples through multi-perspective decoupling of tasks. Our multi-scale models trained on Jedi demonstrate its effectiveness by outperforming existing approaches on ScreenSpot-v2, ScreenSpot-Pro, and our OSWorld-G. Furthermore, we demonstrate that improved grounding with Jedi directly enhances agentic capabilities of general foundation models on complex computer tasks, improving from 5% to 27% on OSWorld. Through detailed ablation studies, we identify key factors contributing to grounding performance and verify that combining specialized data for different interface elements enables compositional generalization to novel interfaces. All benchmark, data, checkpoints, and code are open-sourced and available at https://osworld-grounding.github.io.
Semantic Segmentation with Generative Models: Semi-Supervised Learning and Strong Out-of-Domain Generalization
Apr 12, 2021



Training deep networks with limited labeled data while achieving a strong generalization ability is key in the quest to reduce human annotation efforts. This is the goal of semi-supervised learning, which exploits more widely available unlabeled data to complement small labeled data sets. In this paper, we propose a novel framework for discriminative pixel-level tasks using a generative model of both images and labels. Concretely, we learn a generative adversarial network that captures the joint image-label distribution and is trained efficiently using a large set of unlabeled images supplemented with only few labeled ones. We build our architecture on top of StyleGAN2, augmented with a label synthesis branch. Image labeling at test time is achieved by first embedding the target image into the joint latent space via an encoder network and test-time optimization, and then generating the label from the inferred embedding. We evaluate our approach in two important domains: medical image segmentation and part-based face segmentation. We demonstrate strong in-domain performance compared to several baselines, and are the first to showcase extreme out-of-domain generalization, such as transferring from CT to MRI in medical imaging, and photographs of real faces to paintings, sculptures, and even cartoons and animal faces. Project Page: \url{https://nv-tlabs.github.io/semanticGAN/}
Unsupervised Wasserstein Distance Guided Domain Adaptation for 3D Multi-Domain Liver Segmentation
Sep 06, 2020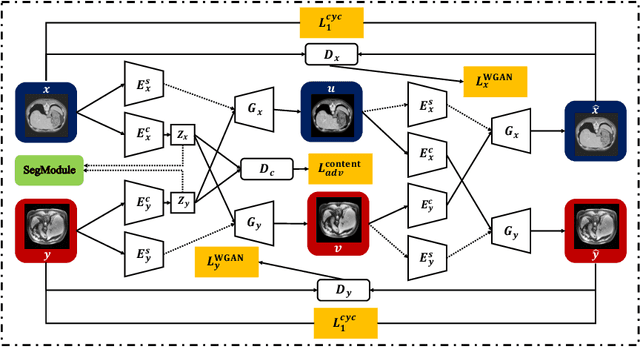

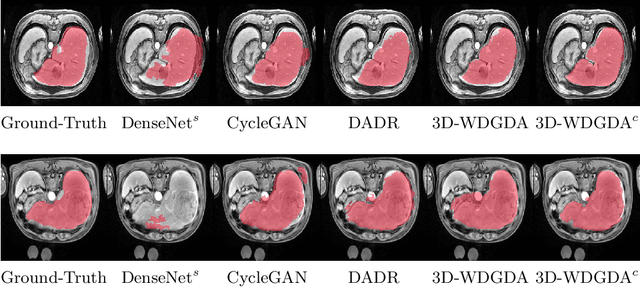

Deep neural networks have shown exceptional learning capability and generalizability in the source domain when massive labeled data is provided. However, the well-trained models often fail in the target domain due to the domain shift. Unsupervised domain adaptation aims to improve network performance when applying robust models trained on medical images from source domains to a new target domain. In this work, we present an approach based on the Wasserstein distance guided disentangled representation to achieve 3D multi-domain liver segmentation. Concretely, we embed images onto a shared content space capturing shared feature-level information across domains and domain-specific appearance spaces. The existing mutual information-based representation learning approaches often fail to capture complete representations in multi-domain medical imaging tasks. To mitigate these issues, we utilize Wasserstein distance to learn more complete representation, and introduces a content discriminator to further facilitate the representation disentanglement. Experiments demonstrate that our method outperforms the state-of-the-art on the multi-modality liver segmentation task.
Robust and Generalizable Visual Representation Learning via Random Convolutions
Jul 25, 2020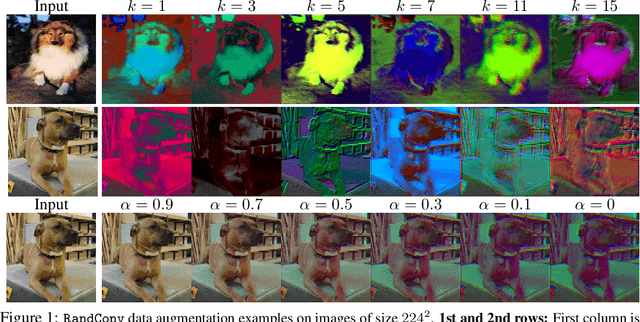
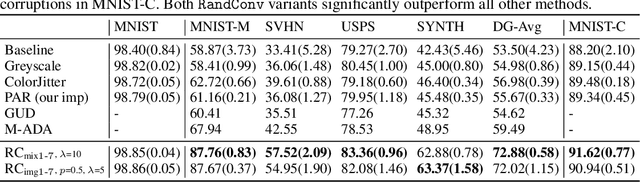
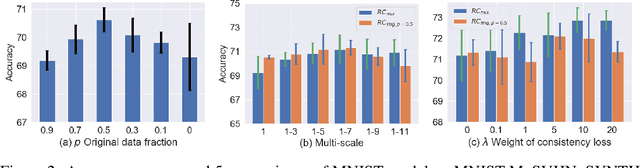
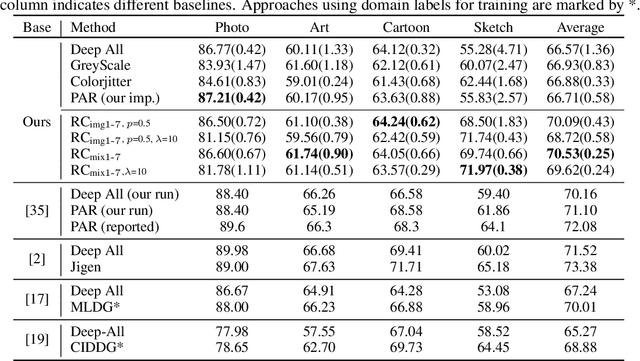
While successful for various computer vision tasks, deep neural networks have shown to be vulnerable to texture style shifts and small perturbations to which humans are robust. Hence, our goal is to train models in such a way that improves their robustness to these perturbations. We are motivated by the approximately shape-preserving property of randomized convolutions, which is due to distance preservation under random linear transforms. Intuitively, randomized convolutions create an infinite number of new domains with similar object shapes but random local texture. Therefore, we explore using outputs of multi-scale random convolutions as new images or mixing them with the original images during training. When applying a network trained with our approach to unseen domains, our method consistently improves the performance on domain generalization benchmarks and is scalable to ImageNet. Especially for the challenging scenario of generalizing to the sketch domain in PACS and to ImageNet-Sketch, our method outperforms state-of-art methods by a large margin. More interestingly, our method can benefit downstream tasks by providing a more robust pretrained visual representation.